Introduction
When various talkers speak concurrently, listeners are required to identify target speech but also to identify location of the target talker for the segregation of competing speech signals. In this everyday listening situation, binaural hearing has been known to provide better speech perception and sound localization over monaural hearing. The advantage of binaural hearing for recognizing speech in noise has been explained in terms of binaural summation, binaural squelch, and head shadow effects.1-3) The use of binaural devices becomes increasingly common to hearing-impaired listeners since the binaural stimulation prevents neural degeneration associated with auditory deprivation.4,5)
Due to an expansion of cochlear implant (CI) candidacy, more individuals are eligible to receive CI.6) In general, people with unilateral CI can detect and recognize target sounds well in quiet listening conditions, yet their performances are greatly decreased in noisy listening situations.7-10) The unilateral CI users can achieve better speech perception in noise through binaural hearing, by either bilateral implantation or bimodal hearing (the use of a CI in one ear and a hearing aid in the unimplanted ear). Although the bilateral CIs are becoming more common, it may not be recommended for all adult users with unilateral CI due to several reasons such as the substantial amount of residual hearing in unimplanted ear, and other health or financial issues.5,10,11)
The advantage of wearing a hearing aid on the unimplanted ear, called the bimodal benefit, has been well documented from objective localization or recognition performance in adult and children CI users.12-18) Although the group results revealed the significant bimodal benefits to speech recognition, some researchers emphasized analyses of the individual bimodal benefits. In addition, research on the subjective reports obtained with bimodal hearing has been limited compared to an extensive body of literature on objective measures. At present, only a few studies have examined both objective and subjective outcomes with bimodal devices.16,19) The studies above showed substantial individual differences in bimodal advantages between outcomes.
Given the issues, the current study concerned not only the group results but also the individual data on both objective and subjective outcomes. Beyond the earlier studies which have mostly used a limited type of materials for objective measure, the present study measured localization and recognition abilities using both environmental sounds and target speech in quiet or with a competing speech. The research questions addressed in this study were as follows: 1) Are there more benefits in bimodal individuals when localizing and recognizing sounds?, and 2) are the objective performances associated with the subjective reports with bimodal hearing?
Subjects and Methods
Subjects
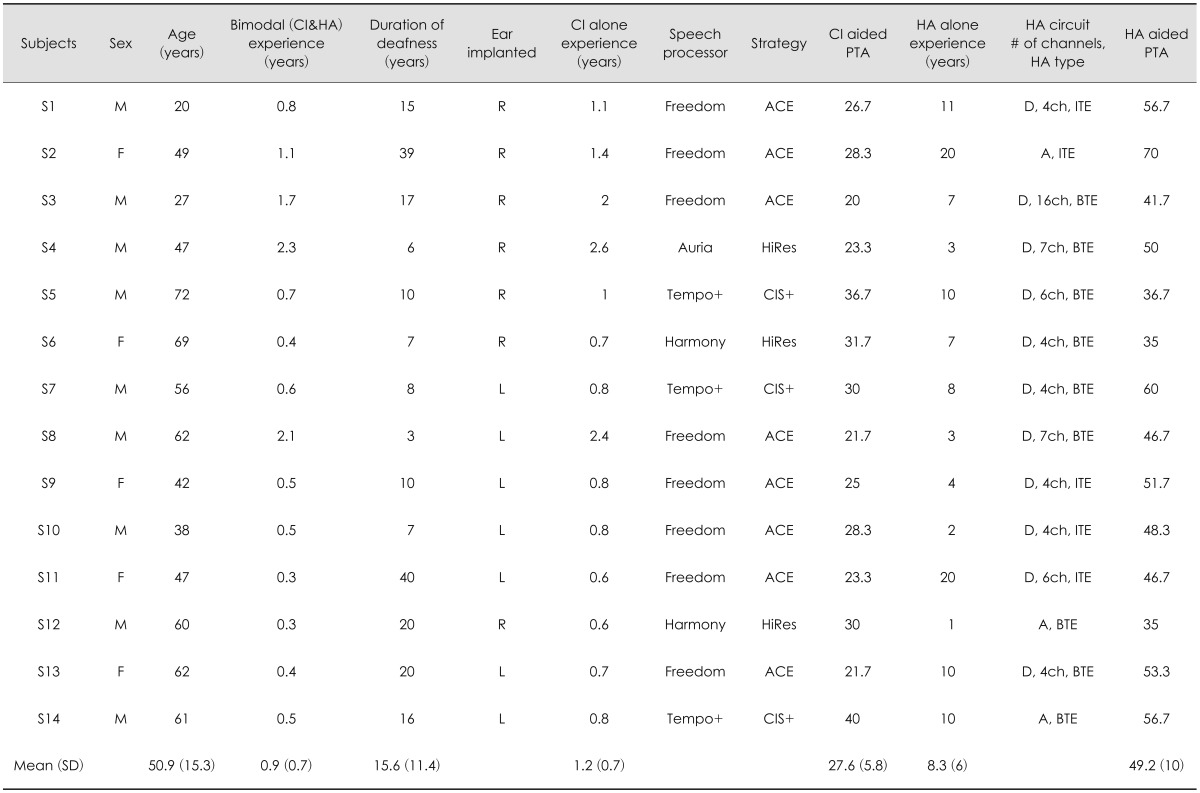
Fourteen CI recipients (mean age, 50.9±15.3 years) participated for the experimental testing. The subjects were all postlingually deafened adults, and their mean duration of bimodal experience was approximately 0.9 years. The mean of puretone thresholds averaged (PTA) across 0.5, 1, 2 kHz with CI alone was 27.6±5.8 dB HL, and the PTA obtained by using hearing aid (HA) alone was 49.2±10.1 dB HL. Table 1 shows the CI participants' demographic information on chronological age, sex, CI or HA aided threshold averaged across 0.5, 1, 2 kHz, and details about cochlear implant and hearing aid usage. For pilot testing, ten normal-hearing adults (mean age, 26.3 years) participated in order to confirm the difficulty level of our testing, rather than for the purpose of group comparison.
Stimuli and test setup
The current study presented environmental sounds and sentences as test materials. As a material of environmental sounds, forty environmental sounds developed by Shafiro20) were used. As speech materials, sentences of the Korean Standard Sentence Lists for Adults21) were used to make three types of speech materials for one-male talker, one-female talker, and two-talker (male target talker with female background talker) conditions. Since the sentences had duration of approximately 4-7 seconds and the environmental sounds had different durations, some short environmental sounds were edited to repeat via Adobe® Audition® (version 3.0, Adobe Systems Incorporated, San Jose, CA, USA) to make them last approxima-tely 5 seconds. All the target sounds were presented at 65 dB sound pressure level and calibrated using sound level meter (Type 2150L, Brüel and Kjær, Skodsborgvej, Denmark) before testing.
Each participant was seated approximately 70 cm from the center of the 8-loudspeaker array that spaced 45° apart in a circle around the participant. Participants were informed of the number of each speaker, and were instructed that one out of eight speakers would randomly present the target sound. On the measurement of localization ability, listeners were required to say the number of the loudspeakers that they thought the target sounds were coming. For the two-talker condition where the target male and competing talkers spoke at the same time, listeners needed to indicate the loudspeaker of male-target source. On the recognition measurement of environmental sounds or 1-talker sentence, the listeners were asked to say the environmental sounds or the sentences they heard. For the two-talker condition, the sentences spoken by target male talker were asked to repeat while ignoring the female's speech.
The abilities of localization were scaled depending on errors between the target speaker and the response speaker indicated by the subject. For example, when the listeners localized the target source correctly, a scale of 5 was given, which was calculated to imply 100%. When the listeners incorrectly responded as one of the two speakers next to the target speaker, a scale of 4 was given. When two, three, and four speakers were deviated from the target speaker source as responses, then the scales of 3, 2, and 1 were taken, respectively. Those scales then were converted to percent correct (%), where the score of 100% represents perfect localization. Scoring sentence recognition was based on the number of key words correct.
Prior to the testing, the user's device settings and programs were verified to be preferred for everyday listening, and were maintained during the experimental testing. For the CI alone condition, the hearing aids were turned off. As practice session, all the participants were familiarized to number the speaker source using speech-shaped noise until the correct numbering of speaker reached 70%. The order of two listening conditions (CI alone, CI&HA) and various target materials (one-male, one-female, two-talker speech, and environmental sound) was randomly selected for each listener.
Questionnaire
After the measurement of objective performances, each participant completed the Korean-version of Speech, Spatial, and Qualities of Hearing scale (K-SSQ) questionnaire.22) The SSQ23) questionnaire was developed to measure a listener's self-reported ability to hear in various listening situations within the three domains.24) First, the Speech domain assesses various aspects of hearing speech in a range of realistic conversational situations involving such as reverberation and multiple talkers. Second, the Spatial domain covers the directional and distance aspects of listening and also the movement of the sound stimuli. Third, the Quality domain examines the degree of sound quality or clarity through various types of sounds. Each domain of K-SSQ includes 50 items, and each item is scored from 1 to 10.22) Here, 1 always represents greater difficulties experienced, while the higher scores reflect greater abilities. Since the purpose of this questionnaire was to determine the relative effectiveness of bimodal devices, participants were asked to report disabilities they experienced in the bimodal hearing. To present K-SSQ results, listeners' answers on each K-SSQ item were converted to percent correct (%).
Pilot testing
To confirm the difficulty level of the experimental testing, ten young normal-hearing adults were evaluated for both localization and recognition as a pilot testing. Results showed that the localization performance of young normal-hearing adults ranged 99-100%, regardless of the test material. The average scores of speech recognition ranged 94% to 100% across the target materials. This verifies that this experimental testing was not too difficult, at least for normal-hearing adults.
Data analysis
Statistical analyses were conducted using SPSS 18.0 (SPSS Inc., Chicago, IL, USA). A two-way analysis of variance with repeated measures was performed to determine the effects of test material (environmental sounds, 1-talker speech, 2-talker speech) and device condition (CI, CI&HA) on localization and speech recognition performances. Any necessary Bonferroni-adjusted post-hoc multiple comparisons were also performed. To further estimate any relationships among objective and subjective measures or any relationships between demographic information and outcomes, Pearson correlation analyses were conducted.
Results
Localization performance
Mean performances of localization (%) are shown in Fig. 1 when the environmental sounds, 1-talker, and 2-talker speech materials were presented. Here, the scores with 1-talker speech show performance averaged across one-male and one-female conditions because of no significant effect of target-talker gender (one male vs. one female) or no related interactions. Statistical results revealed that, on average, the localization scores with CI&HA were significantly greater than the scores with CI alone (p<0.01). The post-hoc pairwise multiple comparison results revealed that the localization performance of environmental sounds was significantly superior to the localization performance of 1-talker speech, which was significantly greater than the scores obtained with 2-talker speech (p<0.01). A two-way interaction between test material and device condition was also significant (p<0.01), indicating that the amount of bimodal benefits differed by the type of test materials.
Concerning the emphasis on individual results in binaural advantages, the present study explored whether all the CI recipients localized better with CI&HA than with CI alone and also whether the individual bimodal benefits in localization performance were consistent across test materials. Fig. 2 shows individual and mean bimodal benefits (score with CI&HA-score with CI alone) on the localization performance. As shown at the far right of Fig. 2, the mean performance improved by 9-12 percentage points with bimodal hearing, regardless of the test material. However, the amount of improvement varied across participants and test materials. When localizing environmental sounds, the bimodal benefits were greater than 20 percentage points to some participants (S4, S9, and S11) while other participants (S2, S12) exhibited little bimodal benefits. When localizing 1-talker speech, three participants (S10, S12, and S13) showed very minimal performance difference between their CI and CI&HA conditions. When localizing 2-talker speech, bimodal hearing provided relatively greater benefits (24-28 points) to some CI recipients (S5, S6, and S7), whereas no improved (S1, S12) or even worsened localization performance (S2) was observed with bimodal stimulation.
Summarizing, bimodal hearing appears to be beneficial to localizing target sounds based on the group-mean data. However, bimodal hearing does not lead to better localization performance to all CI participants. Besides a substantial inter-subject variability in localization bimodal benefits, some participants (S3, S5, and S13) showed a large intra-subject variability in bimodal benefits depending on the test material.
Recognition performance
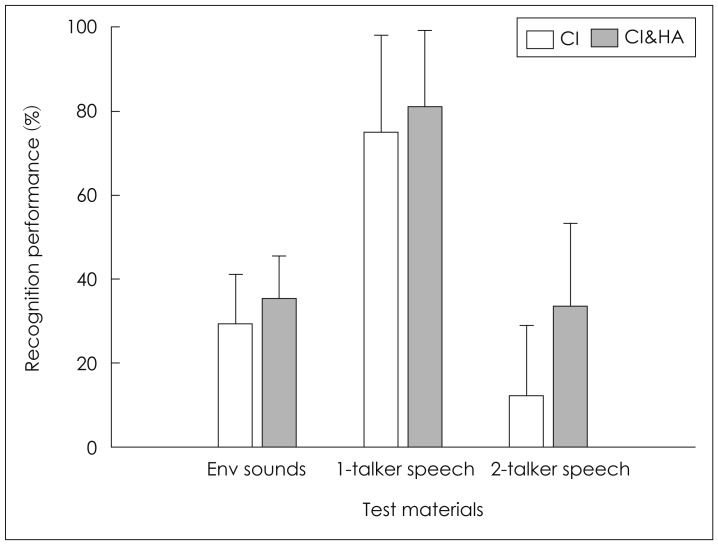
Average recognition scores (%) of the three test materials are plotted in Fig. 3. The recognition scores with 1-talker speech show performance averaged across one-male and one-female talker conditions. Results showed significantly higher recognition scores with CI&HA compared to with CI alone (p<0.01). The pairwise multiple comparisons revealed that the overall performance of 1-talker speech recognition was significantly better than the recognition performance of environmental sounds, which was significantly superior to the 2-talker speech performance (p<0.01). As seen in Fig. 3, the degree of bimodal benefits on recognition performance was substantially greater for the 2-talker speech than for other test materials. This tendency appeared to be significant from a two-way interaction between test material and device condition (p<0.01), due possibly to a greater room to be increased for 2-talker recognition performance with CI alone.
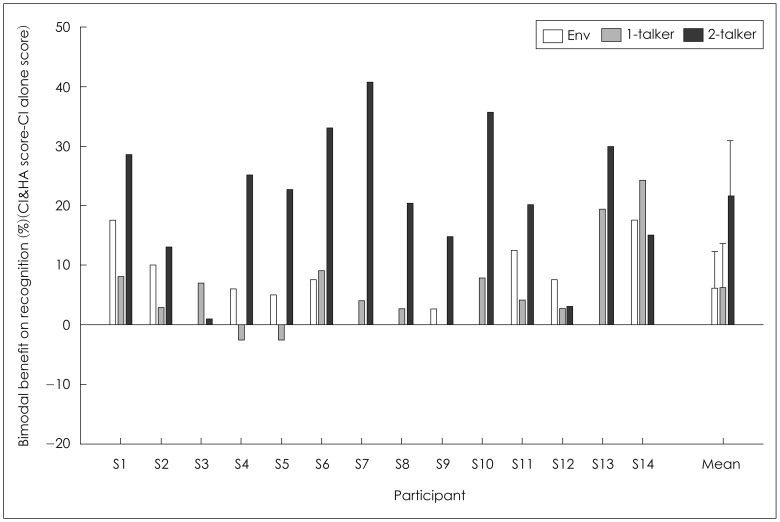
Fig. 4 shows individual and mean bimodal benefits (score with CI&HA-score with CI alone) on the recognition scores. As shown at the far right of Fig. 4, the mean bimodal benefit was approximately 6 percentage points when recognizing both environmental sounds and 1-talker speech. The bimodal hearing facilitated the mean performance of 2-talker speech recognition by about 21 percentage points. Considering the large individual variability in bimodal advantages for localization, a question of how the individual bimodal benefits varied across participants and test materials was also addressed for recognition performance. First, when recognizing environmental sounds, bimodal hearing did not yield any advantage to five (S3, S7, S8, S10, and S13) out of 14 participants. When recognizing 1-talker sentence, the benefits from bimodal device were substantially lower (≤4 percentage points) for five subjects (S2, S7, S8, S9, S11, and S12), and even two subjects (S4 and S5) recognized slightly poorer with CI&HA than with CI alone, as shown in Fig. 4. For the 2-talker speech recognition, bimodal hearing was greatly beneficial (improvement of 30-40 percentage points) to four subjects (S6, S7, S10, and S13), while some subjects (S3 and S12) had minimal improvement with bimodal hearing.
In summary, bimodal hearing facilitated overall recognition performance regardless of the test material. Especially, listeners appeared to have greater bimodal benefits for the 2-talker listening condition, which was more difficult listening situation. However, the notable individual differences in bimodal benefits were observed across participants as well as the type of materials for the recognition performance.
Subjective reports from K-SSQ
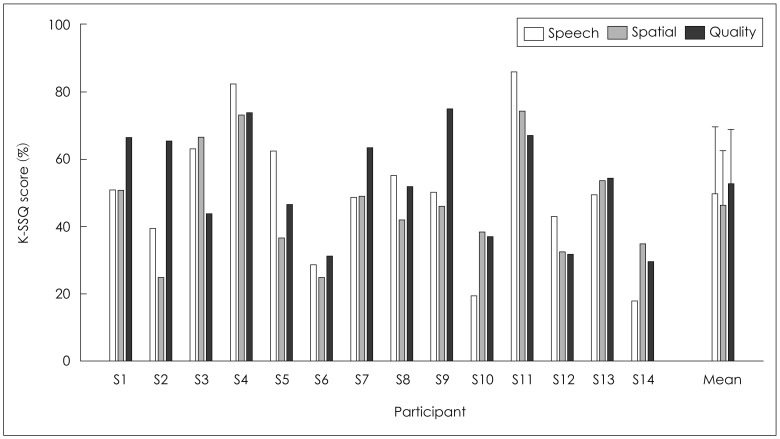
Fig. 5 illustrates individual and mean scores obtained from three domains of K-SSQ, consisting of speech-hearing, spatial-hearing, and quality domains. Mean data showed that, on average, K-SSQ score was 49.59% on the speech domain, 46.09% on the spatial domain, and 52.48% on the quality domain (in total, 49.5%). Results of Pearson correlation analyses revealed that the K-SSQ scores among three domains were all significantly (p<0.05) related to each other. Although K-SSQ responses are entirely based on self-report, this may be indicative of a high interconnection among responses of three domains, meaning that someone with greater subjective benefits on one scale also shows greater benefit on other scales. However, as seen from Fig. 5, some participants' (S6 and S13) subjective ratings seemed consistent across domains whereas some (S2 and S9) showed discrepant results.
Correlation analyses
The present study conducted additional Pearson correlation analyses to address following issues. First, we determined the associations between objective performances and subjective reports obtained with bimodal hearing. Remind that the K-SSQ responses were estimated from three domains, the speech, spatial, and quality domains. Using reports from each of the speech, spatial, and quality domains, it was advantageous to analyze the relations between localization performance and subjective responses in the spatial domain separately from the relationship between recognition scores and subjective reports related to speech and quality domains. Table 2 shows those associations separately. As seen, the spatial-related subjective reports were only significantly (p<0.05) related to the environmental sound localization (r=0.57) or identification (r=0.55), yet not related to other speech materials. The subjective bimodal benefits in the domain of sound quality were significantly (p<0.05) correlated with bimodal recognition scores in all three materials (r=0.54-0.66)(Table 2). However, the subjective bimodal benefits on the speech domain were not associated with any recognition performance. This indicates that the listeners with greater recognition performance seem to have better perceived sound quality such as sound naturalness and clearness, yet not related to the subjective benefits to speech understanding.
Second, the current study examined any relationship between CI participants' demographic information such as age, aided hearing thresholds, bimodal experience, and their objective and subjective outcomes. Results showed that relationships between listeners' demographic information and outcomes were dependent on the test materials or tasks. For the localization of environmental sounds, participants with longer bimodal experience had relatively better localization acuity (r=0.55, p<0.05). However, when recognizing environmental sounds, younger CI users had significantly better identification (r=-0.79, p<0.01) despite no negative relationship between bimodal experience and age. In contrast, the identification of 1-talker speech was significantly correlated with PTA with CI (r=-0.75, p<0.01). A significant correlation was also found between PTA and K-SSQ responses averaged across three domains (r=-0.64, p<0.05).
Discussion
Despite the numerous earlier reports that bimodal hearing yielded significant improvements in localization as well as recognition performance, previous research has seldom focused on the individual variability in the bimodal benefits. As described above, only a few studies emphasized that bimodal hearing was not always beneficial to all CI recipients. Mok, et al.15) reported that 6 out of 14 bimodal users received bimodal benefits for open-set speech perception measures while only 5 of the 14 subjects showed bimodal advantages for closed-set recognition, revealing inconsistent bimodal benefits across test formats. Seeber, et al.17) focused on the individual localization results of 11 CI recipients. Their findings showed that 5 out of 11 subjects demonstrated no or limited localization abilities whereas only one subject had dramatic improvements and the others received bimodal benefits overall. Consistently, the current individual data also revealed a greater individual variability in bimodal advantages across participants and test materials, notwithstanding the bimodal advantage based on group results.
Another study12) separately analyzed the bimodal benefits into head shadow, binaural summation, and binaural squelch effects. The results showed that each of the binaural effects appeared not to be uniform across twelve CI participants, and bimodal disadvantages were even observed from some subjects depending on the location of sound sources. This study illustrated that some subjects were side dominant yet some were more dominant to midline, and so on. Given this, the localization pattern in this study was additionally examined. Here, we found that participants were proficient in localizing the target sounds when sounds occurred from the implanted side, regardless of using either CI alone or CI&HA. However, even though the sounds were presented from the front and back sides, the listeners incorrectly thought that the sounds were coming from the implanted ear. When the sounds were presented from either the implanted ear or non-implanted ear, the localization errors appeared somewhat inconsistent among possible speaker sources. Interestingly, localization errors occurred quite differently across test materials. When localizing the environmental sounds, the participants thought that the stimuli were presented from the back side, regardless of the use of bimodal devices or the CI alone. In contrast, when localizing the target sentences, listeners incorrectly responded that the sounds originated from the front side. Therefore, this suggests that individual variability on localization errors depends on the location of sound source as well as the test material.
As described above, it is somewhat surprising that not many studies yet investigated both objective and subjective bimodal benefits. Thus, this study raised the question of whether the objective and subjective outcomes would be related to each other. Like the objective performance, the individual bimodal benefits on subjective outcomes also considerably varied. However, the association between objective and subjective outcomes depended on the target stimulus and tasks. This finding would be important since various types of target material and task may not be ideal for the clinical purpose. Since the subjective outcomes were evaluated in each of the three domains, the relationships were separately analyzed and described below.
First, the subjective disability on spatial hearing was significantly associated with the localization and recognition performances of environmental sounds. This implies that the listeners who were more accurate at localizing and recognizing environmental sounds actually felt that they could localize sounds more adequately as well as orient the sound direction in various spatial situations. In contrast, this relationship was not observed in performances with 1-talker and 2-talker speech. This suggests clinical implication that localization or recognition evaluation using environmental sounds would be more efficient to predict localization-related subjective functioning compared to the use of speech material.
Second, the quality-related self reports were also associated with recognition performance regardless of the test material. This association may reflect great abilities to process two different types of signals, as suggested by Potts, et al.11) that the SSQ ratings in the quality domain may be related to the ability to process as well as integrate electric and acoustic signals with bimodal devices.
Last, for the speech-related domain, the present study found no significant relationships between speech-related subjective reports and any performances obtained with speech. Similar to this, Ching, et al.16) found that 9 of 21 participants reported better functioning in their everyday life despite having no improvement with bimodal devices in objective measures. Fitzpatrick, et al.19) also reported large individual differences in subjective reports with bimodal devices. For example, 5 out of the 24 bimodal users reported unbalanced sounds from bimodal stimulation, and the negative comments on bimodal use occurred from limited bimodal benefit for speech understanding, reduced speech clarity, excessive noise in the car, and discomfort from the hearing aid use.
As described in correlation analyses, we failed to find any single strong factor to predict individual differences in objective or subjective outcomes. Rather, various demographic factors were related to objective performance or subjective responses. For example, bimodal experience or chronological age appears to play a role in environmental sound performance. Considering that different stimulus processing between CI and HA may complicate sound integration through bimodal input,17) the longer experience may provide better opportunity for using bimodal stimulation input. As described, audibility delivered through CI was more associated with speech identification. Although this study did not directly measure binaural loudness balance or growth, the audibility by bimodal stimulation as well as Speech Intelligibility Index were significantly relevant to speech recognition and localization abilities.11) Although the use of a HA with linear frequency transposition on the non-implanted ear did not significantly influence the bimodal speech recognition,25) further studies are needed on the effect of HA fitting prescription, frequency response slope and gain on binaural loudness balance as well as bimodal advantages.
However, it is essential that more research be conducted on individual bimodal advantages using various measures considering that only a limited number of studies has focused on the relations between objective and subjective outcomes with bimodal hearing. In particular, this study only used K-SSQ questionnaire such that various self-report questionnaires should be further considered for the measurement of subjective bimodal benefits. Another limitation in this study was the presentation of target sound either in quiet or with one competing talker, which might not reflect speech recognition abilities of multi-talker conversation. Since the binaural advantage seems dependent on specific details of the listening environment, this requires further investigations to apply various listening conditions to examine the bimodal benefits.
Conclusion
The current study supports earlier evidence of bimodal advantages, overall. However, the data also illustrates the importance of individual bimodal benefits for localizing and identifying sounds. The individual bimodal benefits substantially varied across tasks as well as test materials. Concerning the discrepant relations between objective and subjective results, clinicians may need to be careful when predicting the subjective bimodal advantages in everyday listening environments from the traditional localization or recognition measures.