Preferred Compression Threshold and Release Time in Quiet and Noisy Conditions for Elderly Korean Hearing Aid Users
Article information
Abstract
Background and Objectives
Listeners with sensorineural hearing loss want to compensate for their narrow dynamic range from appropriate compression functions of hearing aids. The present study aimed to determine which compression threshold and release time of nonlinear hearing aids might affect speech recognition and speech quality judgments.
Subjects and Methods
Ten elderly listeners with symmetrical moderate-to-severe sensorineural hearing loss participated in the study. To compare two compression threshold (31 dB SPL vs. 61 dB SPL) and two release time (50 ms vs. 500 ms) conditions, subjects’ speech recognition was measured using the Korean version of the Hearing in Noise Test in both quiet and noisy situations. All subjects were also asked to rate the degree of speech quality in terms of loudness, sharpness, clarity, and background noise immediately after completing the speech recognition test.
Results
Although no significant difference emerged in speech recognition thresholds between the two compression thresholds in the quiet situation, the compression threshold of 31 dB SPL showed a lower (or better) signal-to-noise ratio of speech recognition compared to that of 61 dB SPL. The release times of 50 and 500 ms did not statistically differ in both quiet and noisy situations. Subjective categories were found to be louder and clearer in the 50 ms release time for quiet and noisy, respectively.
Conclusions
We expect that these patterns of current results will apply for better-fitting protocol of elderly Korean hearing aid users.
Introduction
The wide dynamic range compression (WDRC) of nonlinear hearing aids (HAs) improves the speech perception ability of sensorineural hearing-impaired listeners who have a narrow dynamic range due to loudness recruitment [1]. Among several WDRC factors, the compression threshold (CT), or “knee point,” is defined as the point where compression function starts in the nonlinear mode [1,2]. In this concept, CT is the first stage and critical for effectively providing nonlinear characteristics of the state-of-the art HA. As the degree of hearing loss increases, lower CT is recommended in general [2,3]. However, when being fitted by the HA with a very low CT, the impaired listeners often experience negatively affected speech perception or subjectively perceived speech quality since the low CT does not large enough gain from the input signal [1,3]. Along with the CT, the release time (RT) refers to the time required to deactivate the compression for gain recovery when speech signal falls below the CT [4]. In other words, it occurs between the offset of an input signal that is sufficiently loud to activate the compression and increase of gain to its target value [5]. Although several researchers have argued the potential usefulness of slow-acting compression, HAs with longer RTs are not commonly available because less than 150 ms enhances the speech perception in the syllabic level [6].
Many studies have sought to find the best CT and RT for HA users, yet results thus far have been conflicted [7]. Based on an early study by Nábĕlek and Robinette [8], for instance, rapid compression offers more advantages to impaired listeners than slow-acting compression. Yet Hansen’s study [9] showed that slow-acting compression was better than fast-acting compression for HA users’ perceptual performance such as speech intelligibility and sound quality. Meanwhile, Moore, et al. [10] found no effect of time constants. One possible explanation for such discrepancies might be that these studies were conducted to evaluate different outcomes. In other words, some researchers focused on the effect of time constants on speech intelligibility [8,10] whereas others investigated the effect of time constants using subjectively perceived sound quality [3,9]. Neither objective evaluation scores by a tester nor degree of subjective sound quality reported by the impaired listeners might be neglected in terms of the best HA satisfaction for the user [3]. In its turn, both objective and subjective results should mingle to induce a comprehensive conclusion.
On the other hand, CT and RT are highly sensitive and key factors for listeners who speak different languages as the language includes its own acoustic and linguistic characteristics. For example, Koreans have less energy in the high frequency regions [11], and even Korean listeners with normal hearing have a narrower dynamic range in the low frequency regions [12]. As a result, it could expect that Korean speakers might prefer lower CT to understand the sentences compared to English speakers [6], which warrants the present study. However, most previous studies have tended to focus on the development of the best-fitting formula not for Korean hearing-impaired patients, but those who speak other languages, especially English [2,4,7]. Their results were adapted for the fitting software or procedures by hearing science industry or major manufactures of HA (in US and Euro). Undoubtedly, hearing-impaired patients who speak Korean receive fitting services using them and sometime they feel uncomfortable to hear speech through their HA [6].
Furthermore, many previous studies concentrated on finding effective fitting parameters for new HA users [13,14], thereby largely overlooking patients with HA experience for many years who have auditory- and/or neural-plasticity [15,16]. According to a study of Choi and Lee [16], for a couple of months, CT was changed several times for providing better satisfaction of speech perception to a sensorineural hearing impaired listener with relative narrow dynamic range although it is hard to understand how long is long enough to adjusted [15]. With aging society and consideration of possible population with age-related hearing loss, we also need to find the best CT and RT for old listeners who have some experience from HA and also degradation ability in cognition to understand speech [15]. Barker and Dillon [15] resulted that their old subjects did not prefer 40 dB SPL but did 65 dB SPL. However, they also suggested that acclimatization effects were not a major factor on the perceived benefit of HAs. In sum, the present study aimed to estimate preferred CT and RT under quiet and noisy conditions. Another objective was to identify which of these situations were positively affected by Korean HA users, especially older listeners, to accordingly suggest components of the best-fitting formula for them.
Subjects and Methods
Participants
Ten subjects (7 males and 3 females) participated in this study. Their average age was 73.1 years and the range of age was 61 to 80 years. For the hearing screening, an otoscopy examination, tympanometry, and pure-tone audiometry using air and bone conductions were conducted to confirm the type and configuration of their hearing loss (i.e., symmetrical sensorineural hearing loss). These participants showed a normal tympanogram, and their pure-tone average for 4 frequencies (0.5, 1, 2, and 4 kHz) was 55.13 dB HL [standard deviation (SD): 6.25], having air-bone gaps no greater than 5 dB HL. Their average period of wearing HAs was 9.9 years. Although they have symmetrical hearing loss, the better ear of the two ears (i.e., a fitted ear) was chosen and tested for the present study. More detailed hearing information of each participant is summarized in Table 1. All subjects were native Korean speakers and signed an informed consent form before beginning the experimental procedure.

Participants’ hearing information
Hearing aid parameter
As various characteristics of HA significantly affect listeners’ performance, all subjects applied for a HA with the same conditions designed for the research purpose and developed by Samsung Electronics-namely, behind-the-ear style, 8 channels, and vent-occluded. Then, Hallym Audiology Institute-version 1 developed by Jin, et al. [17] for Korean language specific HA fitting formula was applied and was also individually adjusted except for CT and/or RT variables.
As previously mentioned, there are different benefits of low and high CTs. For instance, the low CT typically sets below 60 dB SPL, which may be used to improve the audibility of the softer components of speech and/or restore loudness perception [15], whereas the high CT (e.g., 60 dB SPL or greater) is used to limit the output of a HA so that it does not exceed the individual’s discomfort levels of loudness and maximizes his or her listening comfort [1,2]. Thus, two CTs of 31 and 61 dB SPL were chosen as the experimental parameters of the present study. In addition, fast or slow RT was adjusted depending on purpose. For the effect of speech intelligibility and sound quality, the commonly used cut-off value of many studies is 200 msec [4,5]. Indeed, an RT as fast as 50 ms may be associated with the fast echo/contour-smearing effect of speech. This can cause reverberation to be proportionately amplified more than the speech and environmental noise to fill in the inter-syllabic gap, thereby adversely changing the consonant-vowel ratio and signal-to-noise ratio (SNR) [6,16]. On the contrary, a slow RT (e.g., 500 ms, which we selected for this study) may allow insufficient gain for soft speech elements following a loud sound and permit artifacts during the slow gain recovery to be audible [3].
Speech perception measurement
After completing the hearing screening tests, all participants were measured for speech perception ability using 25 lists (10 sentences per a list) of Korean version of the Hearing in Noise Test (K-HINT pro 7.2, Natus Medical Inc., Pleasanton, CA, USA) in quiet and noisy conditions. The K-HINT test asked the participants to listen to sentences presented via the HINT equipment, audiometer (Model GSI 61, Grason-Stadler, Eden Prairie, MN, USA), and a speaker in a sound isolation chamber and then repeat them correctly.
First, the K-HINT sentences were administered in the quiet condition to assess the sentence recognition threshold. This was a condition of sentences with no competing noise. The threshold was determined to be a level of 50% correct by a tester. After the threshold for sentence recognition was obtained, the test was also conducted using the adaptive nature of the K-HINT with babble noise fixed at the 65 dB level. For instance, as the SNR score decreased or increased, the listening conditions became more difficult or easier, respectively. In addition, two different conditions of CT (i.e., CT 31 vs. CT 61) were applied for each condition. Two CT conditions were tested under RT 50 ms with all subjects, and two RT conditions were compared at the preferred CT condition of each subject. All test lists were pseudo-randomized.
Subjective categorical rating
After completing sentence recognition tests, all participants were asked four subjective questions in both quiet and noisy conditions while listening to various outdoor sounds, such as speech, vehicles, and wind. The questions included loudness, sharpness, clarity, and background noise while asking degree as 10 scales in each category [2]. Finally, overall preference between CT 31 and CT 61 or between RT 50 and RT 500 compression conditions was simply asked.
Statistical analysis
The statistical analysis was performed using SPSS software ver. 20 (IMB Corp., Armonk, NY, USA). To identify any significant differences in the speech perception threshold under the two CTs and two RTs, a separate paired t-test was conducted for each condition. In addition, to compare the subjective rating for preference, a Wilcoxon signed rank test was conducted. All criteria used for statistical significance in this study were p<0.05.
Results
Experiment I: quiet condition
Comparison of CT 31 vs. CT 61
In the quiet condition, there was no significant difference of sentence recognition thresholds between CT 31 and CT 61 conditions (t=0.015, df=9, p=0.988). The mean of the CT 31 condition (mean: 55.64 dB HL, SD: 9.10) did not significantly differ from that of the CT 61 condition (mean: 55.62 dB HL, SD: 6.41). Although the subjects reported that CT 31 speech was clearer and much noisier than the CT 61 condition, the subjective rating of speech quality did not show a statistical difference between CT 31 and CT 61 for all categories-namely, loudness (mean: 4.6 points and SD: 1.58 for CT 31; mean: 4.6 points and SD: 1.26 for CT 61), sharpness (mean: 4.6 points and SD: 0.84 for CT 31; mean: 4.4 points and SD: 1.35 for CT 61), clarity (mean: 10 points and SD: 0.00 for CT 31; mean: 8.5 points and SD: 2.42 for CT 61), and background noise (mean: 2.3 points and SD: 2.98 for CT 31; mean: 1.4 points and SD: 1.26 for CT 61) (Fig. 1).

Comparison of speech recognition threshold (A) and categorical rating of sound quality (B) for 31 and 61 dB SPL compression thresholds in the quiet condition.
Comparison of RT 50 vs. RT 500
There was no significant difference of sentence recognition thresholds between RT 50 and RT 500 conditions in the quiet condition (t=0.931, df=9, p=0.376). The speech recognition threshold of the RT 50 condition (mean: 55.75 dB HL, SD: 6.71) did not significantly differ from that of the RT 500 condition (mean: 55.06 dB HL, SD: 7.33). However, in the subjective rating, a statistically significant difference in loudness emerged between the two RT conditions. The subjects responded that speech seemed louder in RT 50 (mean: 4.6 points, SD: 0.84) compared to speech presented by RT 500 (mean: 3.8 points, SD: 1.40) (z=-2.00, p=0.046) (Fig. 2). For the rest, there was no statistically significant difference. For sharpness, clarity, and background noise categories, RT 50 and RT 500 had 5.4 points (SD: 0.84) and 4.8 points (SD: 0.63), 9.5 points (SD: 1.58) and 9 points (SD: 2.11), 1.4 points (SD: 1.26) and 1.4 points (SD: 1.26), respectively.
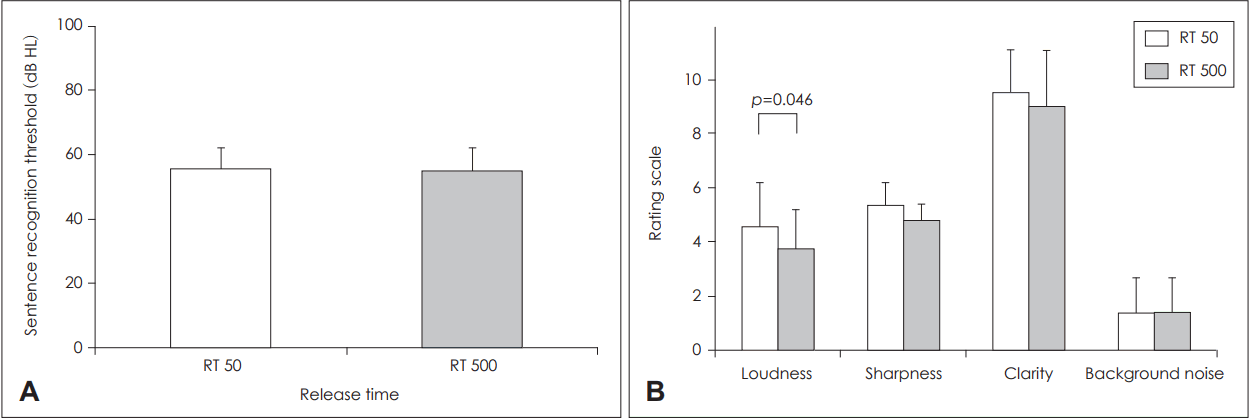
Comparison of speech recognition threshold (A) and categorical rating of sound quality (B) for 50 and 500 ms release times in the quiet condition.
Experiment II: noise condition
Comparison of CT 31 vs. CT 61
In the 65-dB babble noisy condition, a significant difference of sentence recognition thresholds emerged between the CT 31 and CT 61 conditions (t=-2.413, df=9, p=0.039). The mean of the CT 31 condition (mean: 4.65 dB SNR, SD: 2.07) was 1.42 dB lower, which is significant, than that of the CT 61 condition (mean: 6.07 dB SNR, SD: 3.26). The right panel of Fig. 3 indicates the subjective rating scales for four categories when the subjects wore the HA with either CT of 31 or 61 dB SPL. In the CT 31 condition, loudness, sharpness, clarity, and background noise showed 5.7 points (SD: 1.64), 5.2 points (SD: 1.14), 8 points (SD: 2.58), and 1.4 points (SD: 1.26), respectively (p>0.05). In the CT 61 condition, loudness, sharpness, clarity, and background noise showed 5.8 points (SD: 1.03), 5.5 points (SD: 2.07), 8.6 points (SD: 3.10), and 2.8 points (SD: 3.79), respectively (p>0.05).

Comparison of speech recognition threshold (A) and categorical rating of sound quality (B) for 31 and 61 dB SPL compression thresholds in the noisy condition.
Comparison of RT 50 vs. RT 500
The main effect of RT is illustrated in Fig. 4. In terms of background noise, no significant difference of sentence recognition thresholds emerged between RT 50 and RT 500 conditions (t=1.236, df=9, p=0.248). The mean of the RT 50 condition (mean: 6.05 dB SNR, SD: 3.18) did not significantly differ from that of the RT 500 condition (mean: 5.06 dB SNR, SD: 3.10). However, clarity showed a significant difference between the two conditions (z=-1.89, p=0.032), with RT 50 (mean: 9 points, SD: 2.11) providing clearer speech to the listeners than RT 500 (mean: 6.6 points, SD: 3.17). The other categories did not differ statistically in subjective scaling: RT 50 for loudness (mean: 5.3 points, SD: 2.00), sharpness (mean: 4.6 points, SD: 0.84), clarity (mean: 9 points, SD: 2.11), and background noise (mean: 1.4 points, SD: 1.26) and RT 500 for loudness (mean: 5.1 points, SD: 2.13), sharpness (mean: 4.2 points, SD: 1.40), clarity (mean: 6.6 points, SD: 3.17), and background noise (mean: 1.4 points, SD: 1.26).
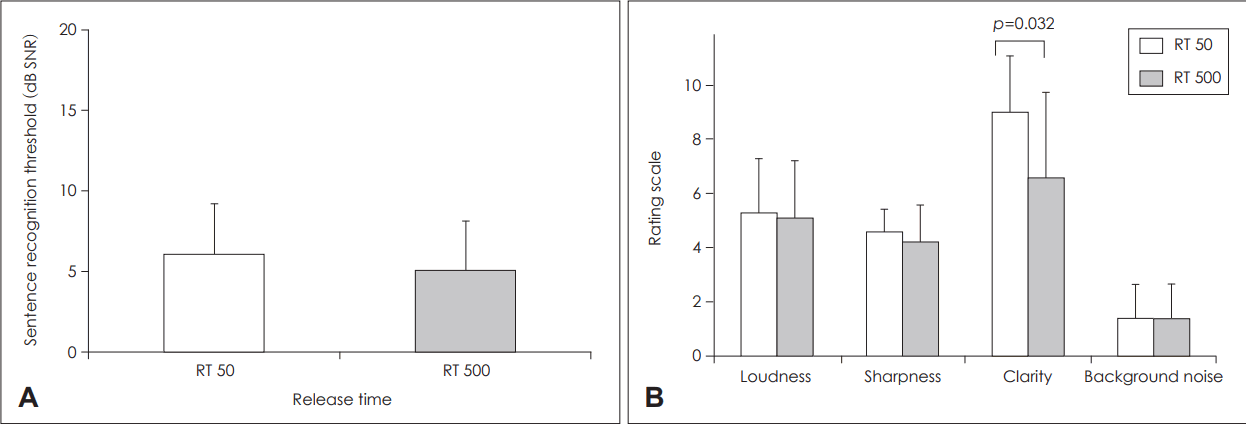
Comparison of speech recognition threshold (A) and categorical rating of sound quality (B) for 50 and 500 ms release times in the noisy condition.
Discussion
The results of Experiment I in the quiet condition revealed no significant difference of speech perception threshold or speech quality judgment between low and high CTs, although seven out of ten respondents preferred high CT. A study conducted by Barker and Dillon [15] supported our results in that their elderly listeners with symmetrical sensorineural hearing loss preferred high CT. Neuman, et al. [3] also showed consistent results: increasing the compression ratio caused decreases in ratings on all scales. This result is completely understandable because a low CT of 60 dB SPL or less makes input speech too soft or compressed [16], which was not preferred and did not offer enough amplification for the impaired listeners with several years of HA experience. However, when background noise was presented (Exp. II), the objective results demonstrated that low CT had a better threshold of speech recognition than high CT. Thus, low level speech sounds could be boosted more and more as CT was decreased, thereby increasing the likelihood of soft speech being heard and understood [15]. The subjects wanted to listen to the speech not at soft levels, but louder with the noise [16], resulting in higher SNR. In sum, the lowest possible CT value would seem to maximize both audibility and loudness comfort with some levels of background noise [15].
At first glance, with no noise, there was no difference in terms of the objective performance in RT, but the subjects seemed to feel it was somewhat louder in faster RT. Ironically, however, slower RT was preferred by seven respondents. When background noise was presented, no difference of threshold occurred between faster and slower RTs. Contrary to this pattern, the subjective rating proposed that subjects felt better clarity in the fast RT. Indeed, regardless of background noise, the elderly listeners with HA experience for several years liked faster RT better. This finding was also supported by overall preference in fast RT being chosen by seven subjects and slows RT being chosen by three. Although some researchers concluded that alternating level differences within the speech utterance might cause a reduction in speech intelligibility with fast RT [5], based on Cox and Xu’s study [18], individuals with lower cognitive abilities such as elderly impaired subjects showed significantly better performance with fast RT. Furthermore, Neuman, et al. [19] obtained positive judgments of sound quality under the fast-acting RT. A recent study by Lee [6] also supported our results in that fast RT improved the consonant-vowel ratio for Korean hearing-impaired listeners. Nevertheless, Neuman, et al.’s [3] result showed that the increasing RT caused ratings of pleasantness to increase and ratings of background noise and loudness to decrease; our data did not find a similar pattern.
The present study has some limitations that should be addressed in future research. First, as our study used only one background noise level of 65 dB, the results could change depending on levels of noise. Neuman, et al. [19] pointed out that sound quality preferences of hearing-impaired listeners were significantly affected by the compression ratio, the competing noise type and levels, and the dynamic range of the listener. Second, we might extend and apply various test materials of sound quality judgment. Because sound quality is a multidimensional attribute, the instructions to the subject were purposely general in order to allow the listener to use his/her own definition of sound quality [2]. Therefore, it is unknown which criteria could benefit subjects. Finally, the current study was restricted to only 10 elderly listeners with sensorineural hearing loss. Further study of the effects of CT and RT with a larger number of participants and various degrees of hearing loss should be conducted to draw generalizations.
Acknowledgements
This work was supported by a grand from Samsung Electronics Co., Ltd. and by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2015S1A3A20 46760).
Notes
Conflicts of interest: The authors have no financial conflicts of interest.