Introduction
Listeners face many challenges under various distracting conditions such as competing background noise and reduced hearing sensitivity [1,2]. Consequently, such challenges may lead to a weakening in their speech understanding ability while simultaneously requiring more intense listening [3], called ŌĆ£listening effortŌĆØ, which can be defined as the exertion the listener experiences by processing information under those conditions [4]. In other words, a great deal of listening effort may imply exhaustion of cognitive resources available for diverse kinds of information processing [3]. Recently, many researchers have started to adopt listening effort tools as an alternative to evaluate speech understanding under noise conditions [5,6]. While emphasizing the effects of age and hearing loss on the listening effort, they have also indicated the importance of application of the listening effort for the hearing aid fitting procedure [7].
Previous studies of the listening effort have mainly investigated by one of the three methods as follows: 1) physiological measurements of pupil dilation or saliva cortisol levels, 2) cognitive measurements of imaging techniques such as magnetic resonance imaging, and 3) subjective ratings of several scaling [8]. Although tools used for these three methods sincerely reflected some changes in the listening effort as the level of noise changed [4], there has so far been no direct comparison between results from the listening effort conducted by different measurements and/or tasks. As a result, researchers cannot make precise interpretations and/or tap related different mechanisms, and will mistakenly come to a superficial conclusion about the listening effort [3].
Contemporary researchers have insisted that listening effort is influenced by two factors [9-11]. First, listening effort is affected by signal degradation, which can result from poor environmental conditions, e.g., background noise. Second, listening effort is affected by biological conditions such as listenerŌĆÖs reduced hearing sensitivity. For example, in the study by Rudner, et al. [3], forty-six listeners with sensorineural hearing loss rated their perceived effort for aided speech perception in noise using a visual analog scale. As we expected, the authors found that there was a strong and significant relationship between rated effort and signal-to-noise ratio (SNR): listeners needed more effort to understand in lower SNR. Interestingly, however, the authors also reported that the relationship between the rated effort and type of background noise seemed to influence to individuals. That is, listening in modulated noise may be rated as more effortful than listening in steadystate noise, although performance was better. Listeners possibly required a measurable difference in the amount of effort needed to concentrate on the speech due to the varying task conditions. This can be interpreted through another factor, namely task dependency, which might control the result of the listening effort. This statement also can be supported by an old law of Yerkes and Dodson [12]. According to the Yerkes-Dodson law, there exists very close relationship between listenerŌĆÖs arousal and performance, while the performance positively increases with physiological or mental arousal. However, when levels of arousal become too high, performance decreases with negative relationship, resulting in a bellshaped curve. In addition, the Yerkes-DodsonŌĆÖs curve was changed by task dependency, i.e., simple-task versus complextask, in terms of its pattern [13]. For a more detailed explanation, two paradigms with a different degree of difficulty were constructed in the study of Bernarding, et al. [14]. The difficulty level was achieved by the combination of the syllables: hard syllabic paradigm for /pa/, /da/, and /ba/ with the same vowel and easy syllabic paradigm for /pa/, /de/, and /bi/ with different vowels. Their results showed that hearing-impaired listeners took a longer reaction time to solve the hard syllabic paradigm than the easy syllabic paradigm. Another study by Panio and Healey [15] confirmed that unfamiliar texts required slightly greater mental effort to understand than familiar text. Their finding revealed that perceived mental effort ratings were significantly lower for familiar texts than for unfamiliar texts, regardless of type of text or distracting condition. Thus, the different level of task paradigm should be measured and compared, although the previous experiments found that level of difficulty simply affected the reaction time [12,15].
The purpose of the present study was to estimate listenersŌĆÖ effort when conducted for single and dual tasks, and then to compare their outcomes and patterns. In the present study, we investigated in two experiments whether decreasing SNR is associated with increasing listening effort and whether the listening effort differs under different task requirements under the same noise condition.
Subjects and Methods
Subjects
Forty-eight young listeners (15 male and 33 female) with normal hearing participated in the study. Their age ranged between 18 and 27 (mean: 20.21 years old). The participants reported a negative history of head and neck abnormalities, ear surgery, otologic disease, and head trauma. They also passed normal hearing criteria at hearing screening tests to ensure Atype of tympanogram and sensitivity of 15 dB HL or better in each ear at 250 to 8,000 Hz and air-bone gaps no greater than 5 dB HL. All participants were native Korean speakers and completed the informed consent form before conducting the experiment. All procedures were approved by the Institutional Review Board of Hallym University (HIRB-2016-048).
Stimuli
For the single task, the Korean Speech Perception in Noise (KSPIN) test was used [16]. For asking the subject to repeat each sentence as he/she heard it, a question tag was removed from the sentence of an original version of KSPIN. In addition, we divided a set of 6 lists of 40 sentences into 12 lists of 20 sentences that included 10 sentences with high predictability and 10 sentences with low predictability. For the dual task, 12 digit lists that consisted of randomized 10 three-consecutive digits were developed [17] and recorded by a native Korean male speaker using the recording function of a smartphone (G Flex 2, LG, Seoul, Korea). While being modified by Adobe Audition (v. 5.0, Adobe Systems, Inc., San Jose, CA, USA), both KSPIN and arithmetic lists were adjusted by root mean square at -20 dB and had a 3 sec of inter-stimulus interval.
Multi-talkersŌĆÖ babble, which was adopted from 20 talkersŌĆÖ babble noise of the developed KSPIN test, was chosen as background noise because a listener needs more effort in the babble noise than in the white noise environment [18,19]. For both single and double tasks, we applied no noise (or quiet), and four SNR ratio (i.e., 0, -4, -8, -12 dB SNR) conditions to obtain percent correct and response time. With a pseudo-random order for the experimental conditions to each subject, stimuli were saved on compact disc (CD). An audiometer (GSI 61, Grason-Stadler, Eden Prairie, MN, USA) connected to the CD player (MM-G25H, Samsung Electronics Co., Suwon, Korea) controlled the presentation level for each subject.
Experimental procedure
After completing the hearing screening, the KSPIN test was performed at the most comfortable level (MCL) for each subject with no noise (i.e., a quiet condition) and four levels of noise composed of multi-talkersŌĆÖ babble (i.e., 0, -4, -8, -12 dB SNRs) with random order. The presentation level for the KSPIN was set to the subjectŌĆÖs MCL initially, and then adjusted so that sentences were equally loud independently of the SNR. Fig. 1 explains the experimental procedure of single and dual tasks and displays their differences in the procedure steps.
The subject was required to write down the sentence on the paper as he/she heard it (Fig. 1A). The arithmetic task was also conducted at each subjectŌĆÖs MCL with the same background noise levels as in the KSPIN test. This required listening to three consecutive digits and then writing the sum of the first and third digits onto the paper (Fig. 1B). For example, after the tester presented three consecutive digits, 1, 8, and 7, the subject wrote 8 in the paper as the sum of 1 and 7. The subject was seated at 1 meter and 45 degrees azimuth from two speakers in the sound isolation room. During the experiment, three audiologists were involved: one for controlling the audiometer outside the booth and the other two for measuring response time using a stopwatch in the booth. The total experiment took approximately 60 minutes for each subject.
Data analysis
First, simple spelling errors were regarded as correct in the sentence recognition, but either context with different meaning or blank was regarded as an incorrect response. In the arithmetic results, either a different arithmetic value or a blank was also confirmed as a wrong answer. Correct responses were converted into a percentage, i.e., percent correct.
Second, the response time was defined from the end of presenting either the sentence or digits to the time when the subject finished writing his or her answer. For accuracy, the subject was asked to insert a slash mark (/) when finishing the task. Two testers simultaneously recorded the response time and the time was averaged.
Statistical analysis
Statistical analysis was performed using SPSS software (ver. 20, IBM Corp., Armonk, NY, USA). To confirm the main effect of percent correct and response time as a function of SNR, each factor was analyzed using a one-way analysis of variance (ANOVA) with repeated measure. If necessary, Bonferroni correction was applied with multiple comparisons. Further, Pearson correlation was performed to analyze the relation between percent error and response time for sentence recognition and arithmetic measures. The criterion used for the statistical significance was p<0.05.
Results
Percent correct of sentence recognition and arithmetic
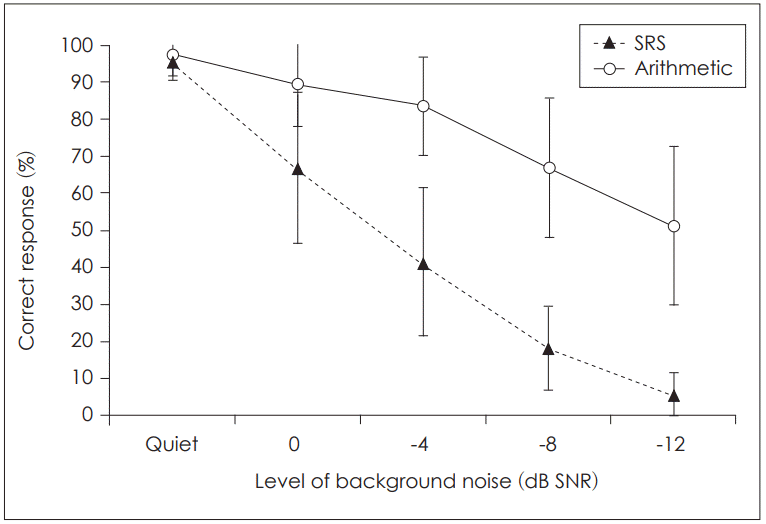
Fig. 2 indicates the percent correct of sentence recognition and arithmetic tasks as a function of SNR. As noise increased, scores for both tasks decreased. The sentence recognition scores showed 95.73% (SD: 0.76) in quiet and then dramatically decreased under the following noise levels: 66.86% (SD: 2.97), 41.35% (SD: 3.64), 18.13% (SD: 3.10), and 5.73% (SD: 1.72) for 0, -4, -8, and -12 dB SNR, respectively. In the repeated measures ANOVA, percent correct at the five background noise levels was significantly different [F(4,188)=366.703, p=0.000] and there was also statistical significant difference among all levels (p<0.05).
On the other hand, arithmetic scores showed 97.08% (SD: 0.76) in the quiet. This was a very similar high score to the sentence recognition task. However, as noise increased, percent correct decreased gradually. 0, -4, -8, and -12 dB SNR conditions revealed 89.58% (SD: 1.68), 83.33% (SD: 1.94), 66.88% (SD: 2.75), and 51.25% (SD: 3.10). The arithmetic task also showed a statistically significant difference of percent correct as level of background noise changed [F(4,188)=86.576, p=0.000]. After Bonferroni correction, the percent correct under the five background noise levels was significantly different (p<0.05), although it seemed there was less effect for arithmetic than for sentence recognition relative to the level of background noise.
Response time of sentence recognition and arithmetic
There was a significant main effect of the sentence recognition [F(4,184)=148.980, p=0.000] and of arithmetic [F(4,188)=14.756, p=0.000] as shown in Fig. 3. In sentence recognition, the quiet condition (mean: 13.50 second, SD: 0.24) was significantly higher than 0 dB SNR condition (mean: 12.64 second, SD: 0.26), which was significantly higher than -4 dB SNR condition (mean: 11.52 second, SD: 0.31). Also, -8 and -12 dB SNR statistically significantly decreased in the response time while showing 9.31 second (SD: 0.39) and 7.16 second (SD: 0.36), respectively. As noise increased, the response time for sentence recognition shortened. However, response time for the arithmetic showed an inverse pattern. That is, as noise increased, the response time increased significantly for the arithmetic task. In quiet, the response time was the shortest among the five background noise levels as 1.37 second (SD: 0.05). 0 dB SNR condition (mean: 1.40 second, SD: 0.05) presented a shorter response time than -8 dB SNR (mean: 1.59 second, SD: 0.06) and -12 dB SNR (mean: 1.72 second, SD: 0.06). -4 dB SNR (mean: 1.47 second, SD: 0.05) showed a shorter response time than -12 dB SNR condition, while suggesting that response time for the arithmetic task was significantly prolonged at approximately 8-dB higher level of background noise compared to the signal level.
Relation between error response and response time
Pearson correlation confirmed a significant negative relationship between error response and response time for speech recognition (r=-0.78, p=0.000) and a significant positive relationship for arithmetic (r=0.38, p=0.000). In other words, response time was shorter as error percent was getting higher in the sentence recognition, but it was longer as the error percent was higher in the arithmetic (Fig. 4).
Discussion
Since listening is an active and dynamic process of attending to information offered by a conversation partner, it can be defined as the process of hearing with intention and attention for purposeful activities demanding mental effort [4,20-22]. In this view, to find how the degree and pattern of listening effort varies as task difficulty varies, we applied a new approach, i.e., task dependency. The present study estimated the listening effort required for a task by using sentence recognition (or single-task) and arithmetic (or dual-task). The results showed that the single-task and dual-task produced very different patterns. It was supported by the curves of Yerkes-Dodson law [12,13]. For the single-task, the scores and response time were very sensitive to the level of noise, and they decreased as noise increased. This pattern seems to a noise effect rather than the listening effort. Conversely, the dual-task showed lower scores and longer response time at higher levels of noise. That is, difficult listening conditions might ask the subject to give more attention and effort [4]. These results can be supported by previous studies by Rudner, et al. [3] The authors derived useful results in that subjectively rated listening effort decreased when SNRs improved, even when SNRs were relatively good. That is, rated effort increased as SNR became poorer. This concept is endogenously modulated, i.e., it depends on attentional resources and requires the aforementioned (higher-order) cognitive effort [14]. Using German digit words from 0 to 9, Obleser, et al. [9] also found a significant right temporo-parietal alpha enhancement during auditory memory retention. In accordance with the prolonged reaction times, the preceding alpha power enhancements during the delay phase reflect the varying cognitive demands. However, Obleser, et al. [9] proposed that the neural consequences of simultaneous adverse listening conditions and cognitive effort are unresolved.
Our results may help to understand unsolved problems from previous studies and to suggest to expand the measuring listening effort. It is acknowledged that one of the main reasons for hearing aid dissatisfaction is the difficulty of listening to speech in noisy environments. Because it is unknown whether the perceptual effects of noise reduction (e.g., intelligibility, listening effort and preference) differ among hearing aids or even among listeners, clinicians have no guidelines for selecting the best noise-reduction system and settings. In other words, if more information were available regarding noise reduction and its effect on the perception of the user, i.e., listening effort, clinicians could actively select the best individual noise-reduction system and settings [22], thereby increasing hearing aid satisfaction [7,23]. As another issue, a greater degree of listening effort required during dialogue between older adults with hearing loss and aged speech has implications for the design of aural rehabilitation plans that go beyond simply improving audibility. The greater degree of listener effort required when conversing with an older speaker may result in poorer comprehension or greater fatigue on the part of the listener, for example, and therefore may impact greatly on that listenerŌĆÖs inclination to engage in such conversation. No significant difference in speech recognition existed when stimuli were derived from younger and older speakers. However, perceived effort was significantly higher when listening to speech from older adults, as compared with younger adults [24]. That study revealed that older listeners with hearing loss exhibited similar levels of speech understanding when listening to the speech of younger and older adults. Although speech recognition was not differentially affected, the listeners with hearing loss reported higher levels of perceived effort when listening to the speech of their older adult counterparts [24]. Any clinical measures that reduce the degree of listener effort required, or otherwise compensate for it, may well promote communication exchanges between older adults [24]. A better understanding of the intrinsic and extrinsic factors that contribute to listener effort is therefore warranted. Future studies would benefit from the inclusion of more challenging noise conditions and speech stimuli from very old speakers-to increase the level of task difficulty and hence further tax the perceptual system. The aging voice may affect not only speech recognition but also the degree of effort required to recognize speech. Particularly for those with hearing loss, the additional effort required in concentrating on listening and understanding can result in considerable fatigue. In some cases, listeners may score highly on speech recognition tasks but report that substantial mental effort was required to complete the task [24]. Some researchers provided quantitative evidence of the effort, finding that for participants with mild-to-moderate hearing loss, the increased perceptual effort required to decipher words produced notable effects on recall performance. Listening conditions, hearing loss including aging issue, and task dependency all play a role in influencing some degree of perceived listening effort [24].
Regardless, the present study still includes some limitations, and thus warrants further ongoing studies. First, since speech and noise was presented by two speakers (i.e., dichotic listening), the current results should be confirmed when applied for diotic listening condition (i.e., simultaneous presentation of the same sound to each ear) [1]. As a second issue, we asked the participants to use paper and pencil technique. This might result in a much longer reaction time to write down the sentences. Arithmetic, on the other hand, which required simply writing down digits, showed a much shorter response time and did not much differ as a function of background noise level. Finally, if using any questionnaire or subjective scaling to measure amount of the listening effort, we may be confident in the current results.
In conclusion, listening effort showed a different pattern based on the kind of tasks, single vs. dual, while the dual-task required dedicated effort by the listeners. These patterns might expand into the neurotology field to discover a mechanism of listening effort in listeners with hearing loss as well as those with normal hearing in further study.